Abstract
Recognizing and generating object-state compositions has been a challenging task, especially when generalizing to unseen compositions. In this paper, we study the task of cutting objects in different styles and the resulting object state changes. We propose a new benchmark suite Chop & Learn, to accommodate the needs of learning objects and different cut styles using multiple viewpoints. We also propose a new task of Compositional Image Generation, which can transfer learned cut styles to different objects, by generating novel object-state images. Moreover, we also use the videos for Compositional Action Recognition, and show valuable uses of this dataset for multiple video tasks.
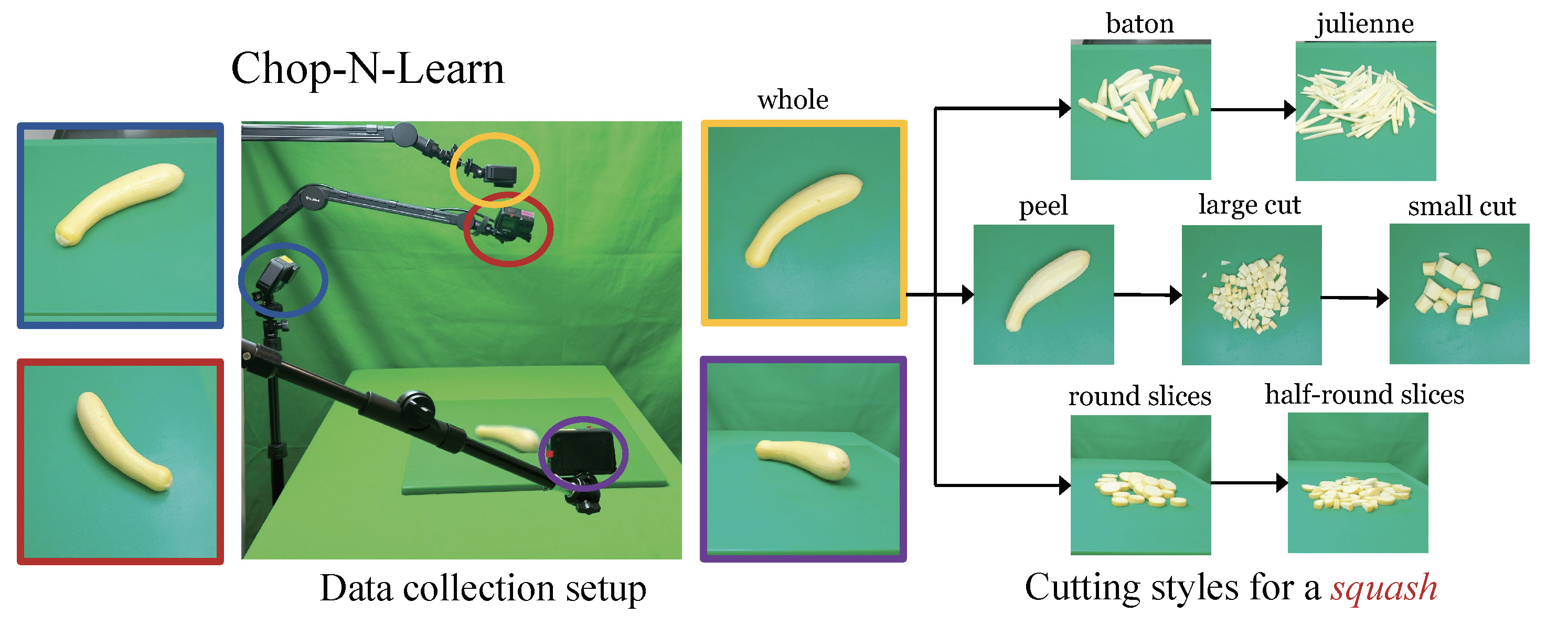
Dataset Collection and Statistics
ChopNLearn is collected with:
- 3 participants
- 4 cameras from different viewpoints
- 20 objects and 7 styles of cutting (+1 with whole)
- 112 compositions of object state pairs
- 1338 images of state-object compositions
- 1260 videos (ranging from 16 seconds to ~12 minutes)
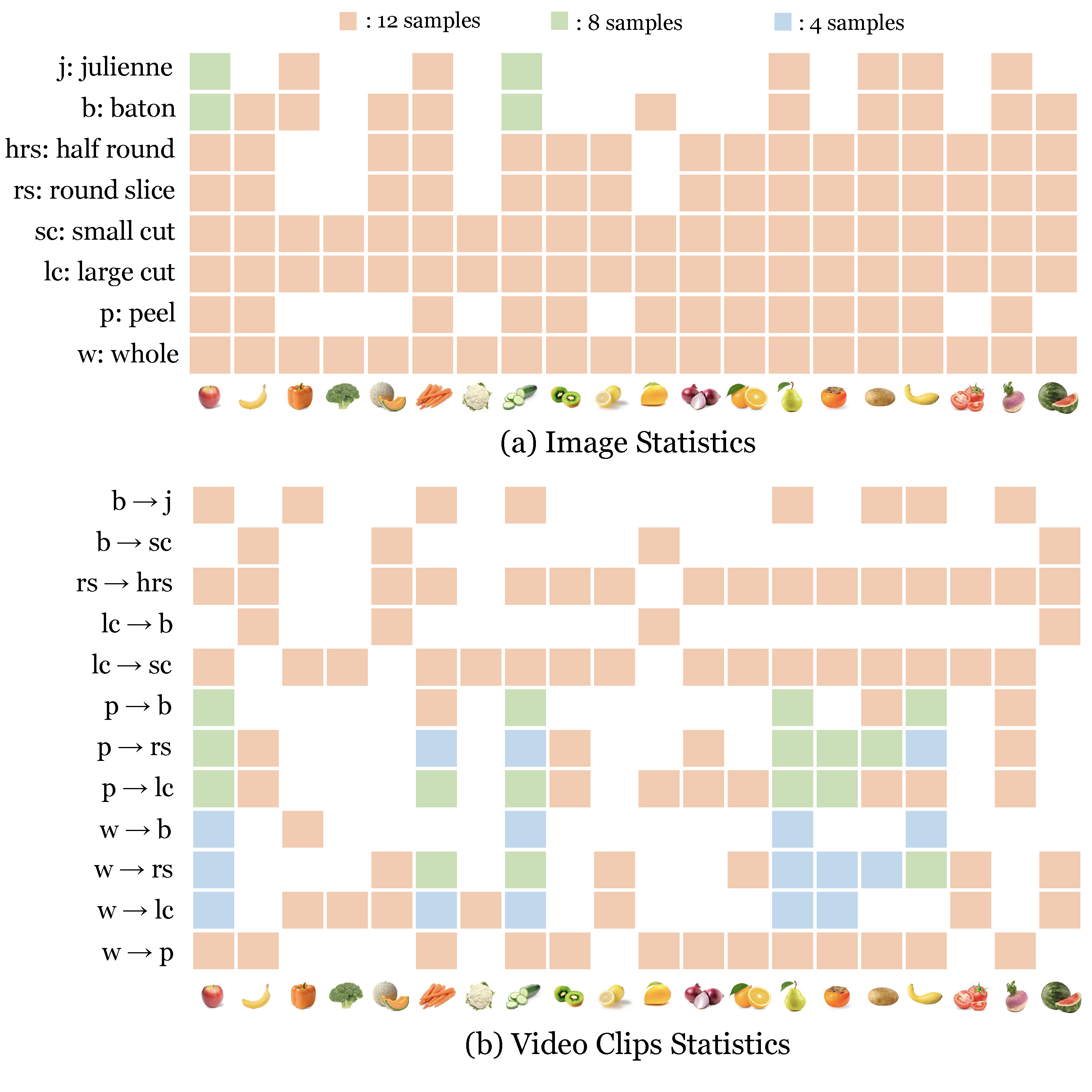
We show the number of samples for each object-style composition in a color-coded manner:
orange represents 12 samples
green represents 8 samples
blue represents 4 samples.
Compositional Image Generation Results
Compositional Image Generation: Given training images of various objects in different states, generate new images of unseen pairs of objects and states.
We consider these methods:
- Stable Diffusion (SD)
- Stable Diffusion + Textual Inversion (SD + TI)
- DreamBooth
- Stable Diffusion + Fine-tuning (FT)
- Stable Diffusion + Textual Inversion + Fine-tuning (SD + TI + FT)
Ground Truth (GT) real images are shown in the first row for reference.
Please select different splits, objects, and states to view the generated images of different compositions.
What else can Chop & Learn be used for?
Capture Long-Term Object-State transformations from Videos
Intermediate state/frame interpolation for Video Generation
Replace green screen with realistic backgrounds

Learn NeRF models for deformable objects
Results of 3D reconstruction using RealFusion.
Input images are shown on the top row, and the corresponding 3D reconstructions are shown on the bottom row.

Pear
Julienne

Squash
Small Cut

Watermelon
Half Round Slices

Potato
Baton

Onion
Round Slices